0 引言
信用卡欺诈行为识别是一个重要的急需解决的问题。信用卡已成为现代生活中非常重要的支付手段,尤其是在欧美等发达国家,信用卡业务体系相当完善,美国的人均持卡数于2017年已达2.9张。信用卡欺诈问题不仅令信用卡持有人和银行遭受巨额经济损失,还会对银行的安全信誉造成负面影响。由此,建立合理、有效的信用卡欺诈识别机制刻不容缓。
现阶段,信用卡欺诈识别主要采用了以人工为主、计算机为辅的识别机制,近年来,由于交易量激增,庞大的交易量对数据处理方法的要求很高,传统的信用卡欺诈行为识别的方法已不能满足实际需要。此外,信用卡交易记录的数据集天然地存在严重的数据不平衡问题,即合法的交易量远超欺诈交易量,为行为识别带来了很大的障碍,对信用卡诈骗识别机制提出了更高的要求。
1 文献综述
1.1 信用卡欺诈行为检测中的机器学习方法
鉴于信用卡交易数据体量、来源、欺诈行为特征的复杂性,多种机器学习用于欺诈识别领域以适应不同体量不同来源的繁杂的交易数据。原理上,这些机器学习方法的基于模型真值与期望值的比较,分析持卡人正常与非正常消费的模式特征,从而在未来的交易中准确识别非正常交易,并提供预警。
1.1.1 监督学习方法
监督学习方法使用标注数据进行训练,常用模型包括回归类、决策树和神经网络三大类。
回归类方法被认为是最简单、直观、有效、可解释的监督学习方法。其中逻辑斯蒂回归是一种传统欺诈检测的统计方法,逻辑斯蒂回归中的回归系数可用于估计模型中自变量的胜率,研究的适用范围比特征分析更广泛。
决策树也是用于欺诈检测的监督学习工具,它可以用于处理连续数据。决策树有许多优点,例如高灵活性,它是一种没有任何数据分布概念的非参数方法,以及它的可解释性,这也是它能得到多样化利用的原因。决策树构建的的基本问题是如何构建一个高精度,小规模的决策树。Kokkinaki提出了相似树的概念。相似树已证明了结果可用于决策树,尤其是其他类型的欺诈,归纳决策树,以建立入侵检测系统。在Prajal Save的决策树方法中,定期更新交易数据的思想已引入研究过程。
神经网络(Neural Network)被认为是最强大的工具之一,并得到了广泛的应用。 GANN是受Wheeler&Aitken结合意识形态(2000)启发的组合产品。在GANN中,遗传算法用于参数的合理选择,而神经网络将对通过遗传算法选择后的的基因组中进行编码。GANN过程涉及生成多个随机个体,神经网络的设计是根据有助于评估参数的基因信息而来,模型的表现在反向传播训练之后得到确定。GANN完美弥补了GA和NN的限制。
1.1.2 其他机器学习方法
其他一些工具也有利于信用卡欺诈检测。隐马尔可夫链是一种新颖的方法, Shailesh S.Dhok和G.R.Bamnote使用隐马尔可夫模型模拟了信用卡交易处理中的操作顺序。隐马尔可夫模型使用持卡人的正常行为来进行训练,并且它在黑匣子中工作,隐马尔可夫模型有助于获得高欺诈检测精度和低误报率(false positive rate)。
1.2 自动化信用卡欺诈识别的挑战
在既有的方法中,基于机器学习的信用卡欺诈识别实践主要存在两方面的挑战:标注数据极度不平衡、成本与有效性的权衡。
1.2.1 标注数据极度不平衡
标注数据不平衡是信用卡欺诈检测中最主要的问题之一,即在信用卡交易数据当中只有极少部分属于欺诈行为,绝大多数属于正常交易行为。采用不平衡的标注数据训练机器学习分类器,如不采用针对性处理方法,将不可避免的导致分类器偏向数据集中占多数的一类,甚至产生单边分类器,对模型训练效果产生负面影响。标注数据不平衡不是信用卡欺诈问题所独有的,也常见于各类实际应用数据集中。合理解决信用卡欺诈预测中的数据集不平衡问题将对解决广泛实际应用中的类似问题提供可靠参考。
1.2.2 成本与有效性的权衡
在机器学习方法的实际应用中,成本与有效性的权衡直接影响了模型评价标准和训练方式。从机器学习分类器的角度,每一笔正确分类和每一笔类别之间的错分均代表权重相同的一个事件。然而在实际应用中,每一笔交易都存在着其独特性,即是由不同实体产生的不同数额的交易,因此每一笔信用卡欺诈事件的监测成本是可变的潜在损失而不是固定的错误成本。在这种情况下,必须在机器学习模型的基础上,进一步考虑实践的需要,建立误差成本测量模型以保证模型成本效用比最大化和可行性。
2 方法
2.1 数据
本次研究所用的数据来自于开源、已做匿名化处理的信用卡交易数据集,包含284807笔交易记录。每笔记录含一个分类变量(欺诈与否)与30个匿名化特征(比如,时间点、金额)用预测检测欺诈行为,其中欺诈交易492笔,仅占全部交易量的0.173%。
2.2 机器学习方法
在本文的控制实验中,我们采用了同一训练数据集训练了多种模型以供比较,包括逻辑斯蒂回归、决策树、集成学习等,并且在训练模型的不同阶段,引入合适的技术指标以进行模型评价。本研究主要测试和对比分析三类主要的机器学习算法对于信用卡欺诈行为识别的预测能力,包括1)回归算法;2)树算法;3)集成学习方法。
2.2.1 回归算法——逻辑斯蒂回归
在控制实验中,采用的回归算法是逻辑斯蒂回归算法。逻辑斯蒂回归基于线性回归方法发展而来,其主要思想是根据现有数据对分类边界线建立回归公式,以此进行分类。Logistic Regression的损失函数可以表示为:
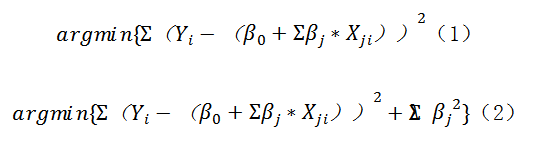
在训练数据有限或over training时,常常会导致过拟合(overfitting),正则化方法主要着眼于解决这一问题,通过向原始模型引入与系数相关项(2),防止过拟合并提高模型的泛化性能。在本例中,最小化逻辑斯蒂的损失函数,不仅解决了模型过拟合的问题,也实现了特征的自动选择,去掉了不包含有效信息的特征。Logistic Regression作为二元分类器也存在一定的限制,即其决策边界是有一个单一的线性方程所决定,无法很好解决具有复杂或非线性决策边界的分类问题。
2.2.2 决策树
决策树模型相较于Logistic Regression而言,可以对很好的对数据集作出非线性分割。同时,树状模型更接近人的思维方式,产生可视化的分类规则,产生的模型具有可解释性,能解决复杂决策边界的分类问题。作为典型的机器学习方法,Trees反映了对象属性与对象值之间的一种映射关系,不受数据集本身的经验分布假设的影响。
2.2.3 集成学习
集成学习指的是是使用一系列学习器进行学习,并使用某种规则把各个学习算法进行整合从而获得比单个学习器更好的学习效果的一种机器学习方法。
3 训练结果与比较分析
3.1 探索性数据分析和数据预处理
在本实验中,使用的数据集含284807笔交易记录,使用了30个预测变量(含Amount与Time)。为了保障训练模型的有效性,我们首先对预测变量的多重共线性进行了检测。检验的结果显示,30个预测变量之间不存在显著(≥0.5)的共线关系(图1)。
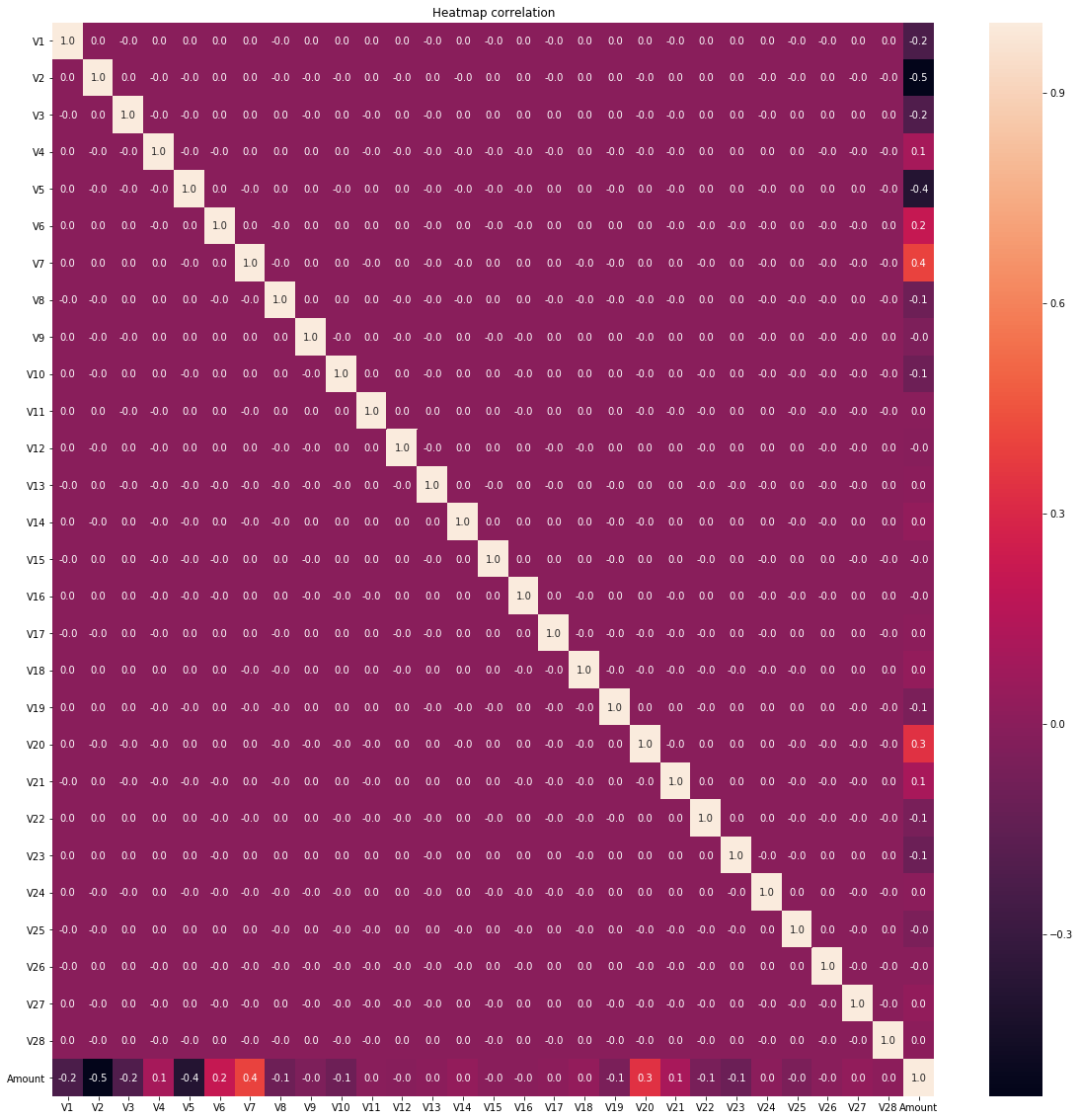
图1 各预测变量之间相关性
通过对金额分布(图2)的检验,重尾分布拟合模型的R-square值为0.712,进一步说明了消费金额分布在低金额处有很强的聚集性,为后续模型的评价与选择提供了一定的参考价值。
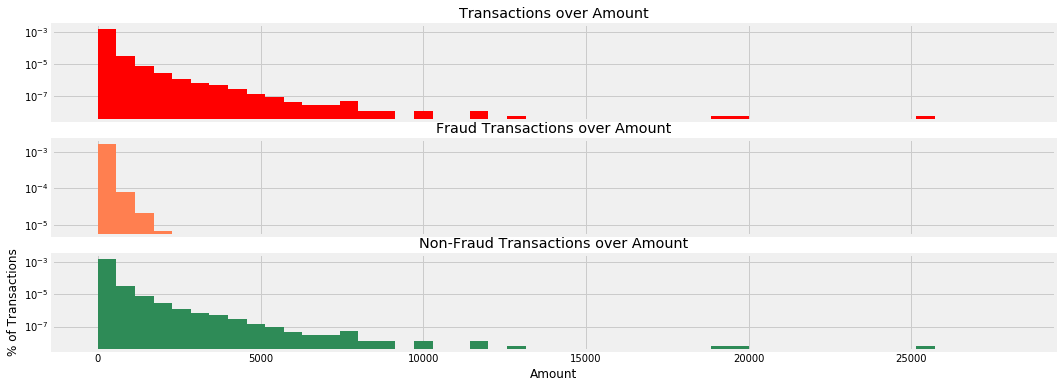
图2 欺诈交易与正常交易的统计分布
整体数据集被划分为训练和测试数据集。我们应用了多种方法来处理信用卡欺诈识别中不平衡数据这一典型问题,并且对这些方法的表现进行了比较。在比较中,所有的案例都采用同一组特征变量,同一标签变量和同一组训练和测试数据集。模型训练仅采用训练数据集(80%),测试数据集完全独立于训练数据集(20%),用于独立测试模型预测效果。由于本案例涉及不平衡数据集,在训练测试样本划分的过程中,正负样本的比例严格保持统一,以保证测试结果的代表性。
3.2 模型预测能力的对比分析
本研究中,模型训练的过程大致可以分为三步:①建立基本的baseline model;②在Baseline model的基础上调整参数,以AUC作为主要衡量标准,找到最为合适的参数组合;③计算得到混淆矩阵,并用于实践分析。
表1 各机器学习模型的模型评价结果
|
| FP Rate(0→1) | FN Rate(1→0) | AUC |
| Logistic Regression | 0.03649 | 0.08163 | 0.972 |
| Decision Tree | 0.05594 | 0.07143 | 0.936 |
| Random Forest | 0.02697 | 0.08163 | 0.945 |
| Ada Boost | 0.02242 | 0.09184 | 0.979 |
就AUC数据来看,逻辑斯蒂方法虽然是最为基本的分类方法,但是在本预测问题中其最终的表现丝毫不逊于集成学习方法,分类效果优于同一个数据集下的决策树模型与随机森林模型。Bagging类方法,包括决策树与随机森林,AUC表现与其他方法的AUC表现有较大的差距,对于数据集的预测效果一般不及0.95。
对比决策树与随机森林方法,随机森林在决策树的基础上进行了随机预测变量的选择,多棵树的叠加也进一步减少了随机森林模型的预测误差,随机森林相较于决策树的预测改进在AUC上有明显的体现。就FP rate与FN rate而言,随机森林主要的预测误差集中在错误地将欺诈交易识别为合法交易。
对比Bagging类方法(随机森林)与Boosting类方法(AdaBoost),在本例中Boosting方法对于通过对弱分类器的优化效果显著,AUC技术指标得到了显著的提升。虽然对于正常交易的识别准确度不及随机森林模型,但是对于欺诈交易的识别准确度有一定的提升。
4 讨论:欺诈成本分析
机器学习模型误差的现实意义对选择合适的信用卡欺诈识别方法也尤为重要。在目前高发的信用卡欺诈案件中,信用卡欺诈(FN)的损失承担方是银行,这一部分因未能识别欺诈产生的直接损失全部归属于银行。过于敏感的信用卡欺诈监测系统(FP)虽在某种程度上降低了上述来源的欺诈成本,但是人力监测成本有所增加,频繁的欺诈预警也会减少客户交易总量影响银行的利润。如何平衡不同来源成本间的关系来选择更优模型是一个值得深思的问题,针对本案例中不同机器学习模型的损失分析对于信用卡欺诈监测模型的合理性选择有很强的现实意义。本文分析结果如下:
从误报角度来看(FP),分别讨论各个模型对于大金额FP-large(>3500)和小金额交易FP-small(≤3500)的预测能力。分析发现,逻辑斯蒂回归对于大金额的误报概率极高(FP-large=1)(图4),随机森林模型的大金额误报概率达0.87。在大金额误报概率角度来看,决策树与AdaBoost有更优的表现(FN-large<0.7)。在小金额误报的预测中,AdaBoost的整体误报概率最低,随机森林次之,逻辑回归的小金额误报概率远高于其他模型。综合来看,逻辑斯蒂回归会带来最高的误报频率,导致使用该银行信用卡的频率降低从而影响总利润。
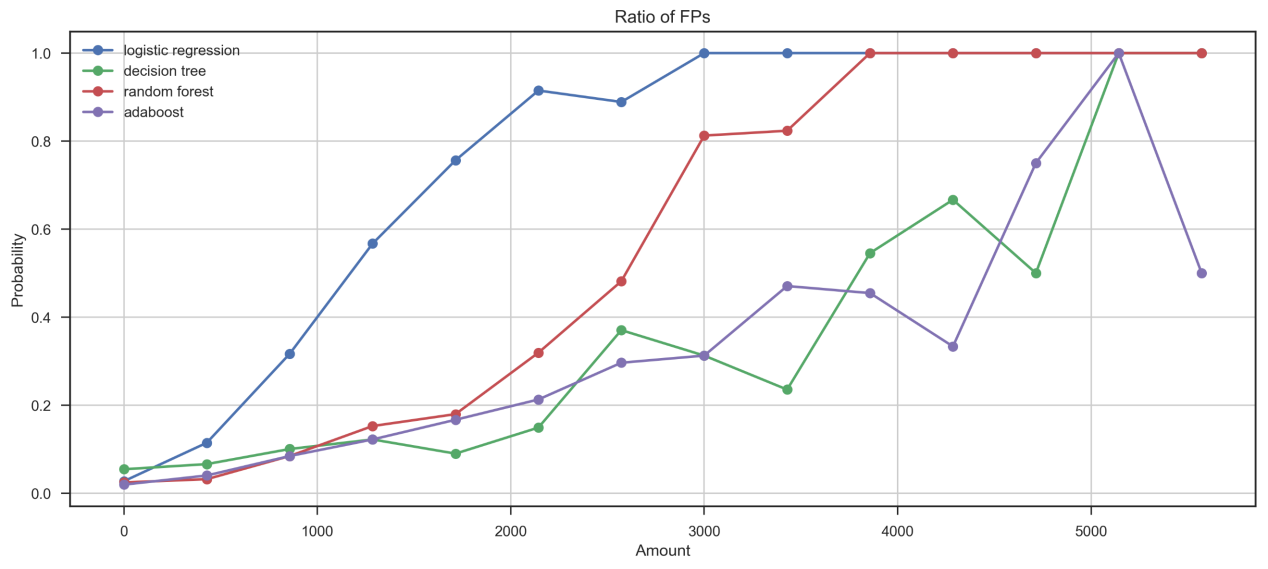
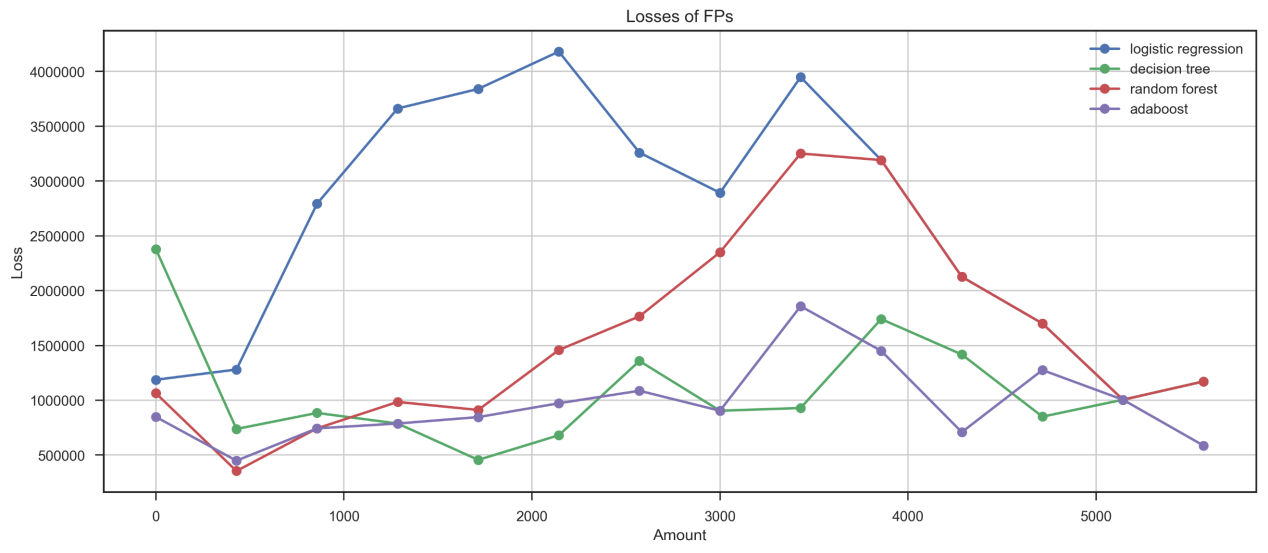
图3 FP交易的预测概率与交易数量分布
从未能识别欺诈交易角度来看(FN),也将分别讨论各个模型对于较大金额FN-large(FN>1100)和极小金额交易FN-small(≤1100)的识别能力。4个模型整体来看(图5),对于较大金额交易欺诈的漏判概率为0(FN-large=0),即在较大金额欺诈交易中,各机器学习模型均不存在漏判欺诈交易的情形。从未能识别欺诈交易的总损失角度来看,随机森林($1,826.5)的因未能准确识别欺诈交易带来的总损失远高于其他模型,AdaBoost($1,187.61)次之。在FN角度的分析中,AdaBoost与随机森林的漏判欺诈概率与因漏判欺诈交易而导致的直接经济损失均较高,逻辑斯蒂回归与决策树模型在漏判欺诈交易这一维度的评估中有更好的表现。
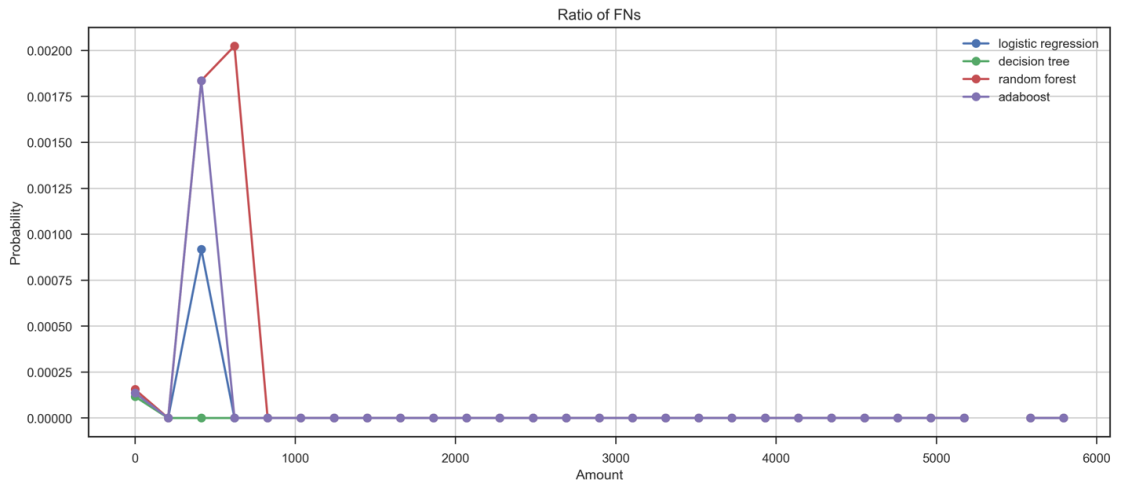
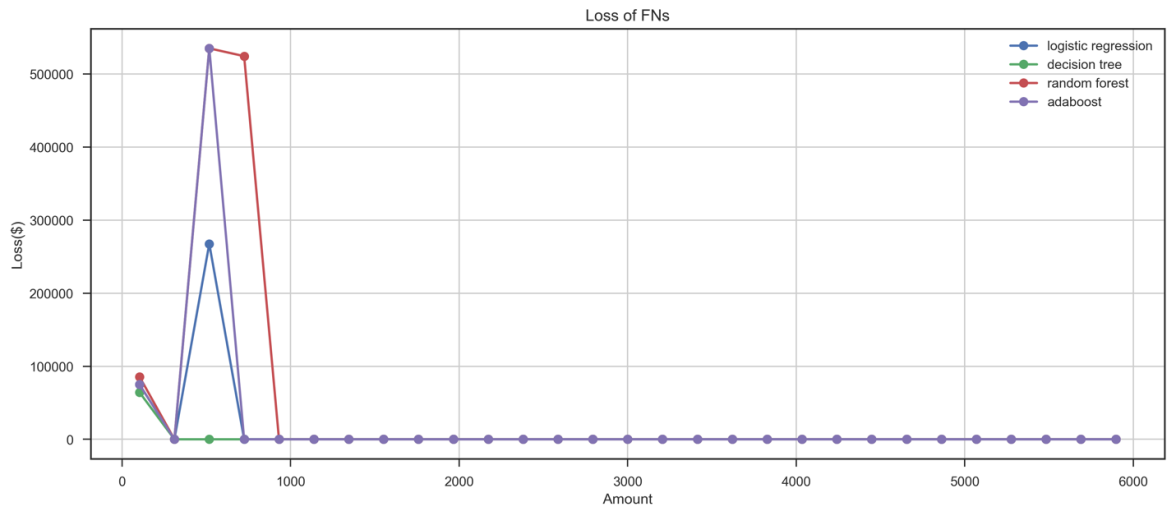
图4 FN交易的预测概率与损失分布
从而,我们不仅可以计算在信用卡欺诈模型中错误分类的总成本(假定从每一笔交易中的手续费为1.75%,图6),也可以分别观察到每一个模型分别在第一类错误与第二类错误下的优劣,这将为银行选择合适的信用卡欺诈识别模型提供参考。
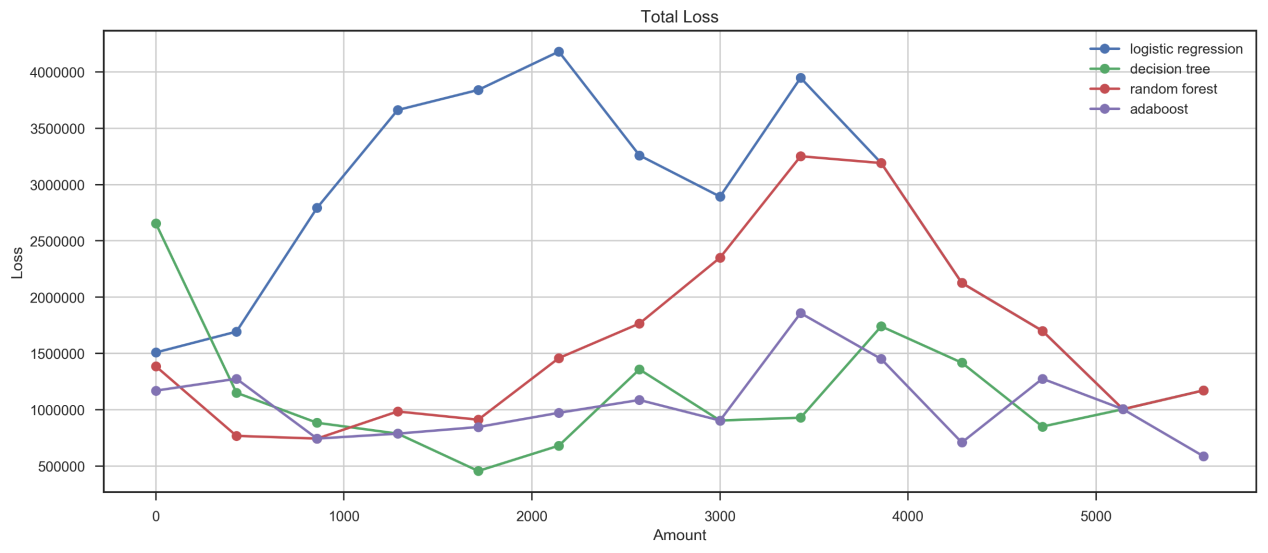
图5 信用卡欺诈识别错误带来的总损失
7 结论
在上文所述的实验中,我们使用了同一数据集和四种不同的机器学习方法来探测机器学习方法在具有高度不平衡特征的信用卡欺诈数据集识别任务中的表现和不同方法的优势和限制,并创新性的从欺诈行为经济成本的角度分析了不同机器学习方法对于不同金额交易中欺诈行为识别的能力差异。
在分类评价指标上表现出色的模型,在经济损失的角度并不一定是最优模型,逻辑斯蒂回归是很好的佐证。本文的结果与讨论表明,信用卡欺诈识别问题并不能被视为单纯的分类问题,模型的最终选择取决于银行需求,即期望更少的直接欺诈损失或是欺诈交易波及的范围更小,预期未能识别出的漏网之鱼数量更多还是金额更高之间的权衡。在以上考量下定义合适的模型评价标准是获得具有最佳实践意义的信用卡欺诈行为识别模型的关键。本文从欺诈成本的角度对各个机器学习模型对于不同金额交易分类能力的分析为今后的相关实践提供参考。
参考文献
[1]P. K. Chan,L. Ave,N. York.Distributed Data Mining in Credit Card Fraud Detection Introduction[C].IEEE Intell. Syst. Spec. Issue Data Min.,1999:1-17.
[2]Yufeng Kou,Chang-Tien Lu,S. Sirwongwattana, and Yo-Ping Huang, “Survey of fraud detection techniques[C].IEEE International Conference on Networking,Sensing and Control,2004(2):749-754.
[3]R. J. Bolton,D. J. Hand,F. Provost,,et al.Statistical Fraud Detection: A Review[J].Stat. Sci.,2002,17(3):235-255.
[4]N. Save Prajal,Tiwarekar Pranali,ain,Ketan N,et al.A Novel Idea for Credit Card Fraud Detection using Decision Tree [J].Int. J. Comput. Appl.,2017,161(13):975–8887.
[5]C. Liu,Y. Chan,S. H. Alam Kazmi,et al.Financial Fraud Detection Model: Based on Random Forest [J].Int. J. Econ. Financ.,2015,7(7).
[6]Ghosh,Reilly.Credit card fraud detection with a neural-network [J].Twenty-Seventh Hawaii Int. Conf. Syst. Sci.,1994(3):621-630.
收稿日期:2018-09-05
作者简介:陈沁歆(1997-),女,上海人,西南财经大学统计学院学生,研究方向:机器学习。





