1 系统设计
1.1 目标和意义
这是一款基于Android平台的图书查询应用APP。主要是面向那些有着阅读兴趣和一定的图书查询网站或应用APP使用经验的人,计划将此APP推广出去后,使用人数争取向四位数靠拢。这个APP的立意是适应大众不断变化的阅读需求和品味,因此绝不可能是一成不变的,APP会伴随着时间的推移而不断完善和发展,必须时时刻刻与人们的实际要求相贴切。所以,此APP的另一目标便是利用自己的特色吸引大众的眼球,从而产生一批固定使用的长期用户,预计要达到5年以上。
此APP的面世,将在很大程度上弥补目前的图书查询网站和应用APP的缺陷和漏洞。例如,此APP将以极简的形式呈现出来,但书籍存量和质量都会严格把控,搜索结果会非常贴合用户的描述,图书简介、书评、相关书籍应有尽有,另有热门推荐这一项功能,会在最大限度上满足用户的需求。通过推广这一APP,人们查询图书的工作效率将会有所提高,人们的阅读生活也将更加便利。
1.2 流程设计
作者使用在线流程图设计工具ProcessOn对应用的流程进行了详细的设计,如图1所示。
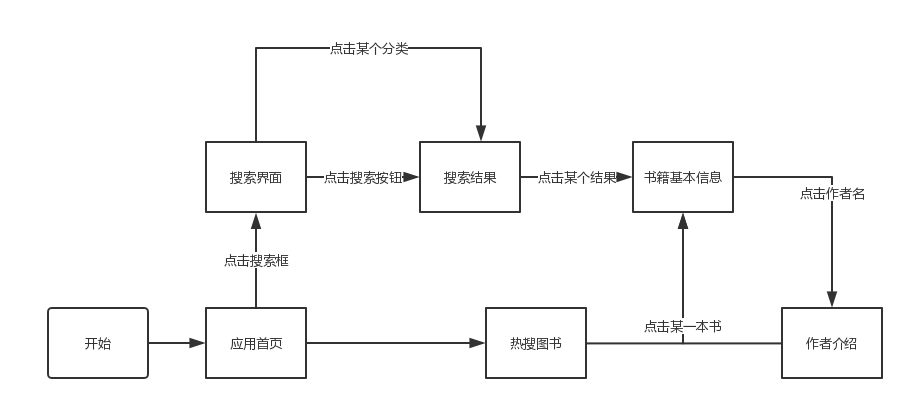
图1 图书管理应用流程图
关于流程的设计,首先用户打开应用程序会直接进入应用首页,在首页中有两个主要部分,分别是热搜图书部分和搜索部分,下边分别介绍。
1.2.1 热搜图书部分
这个APP会同时有很多用户使用,应用后台会自动记录查询量比较多的图书,并将其记录下来,排序之后推荐给所有使用APP的用户,因为很多人都查询的图书肯定是有其价值在的。除此之外,本文也参考了今日头条的推荐模式,自动学习用户感兴趣的图书种类,并且在热搜图书部分着重推荐用户感兴趣的图书种类。
1.2.2 搜索部分
用户如果想查询某些图书的话,可以直接在搜索框内输入内容进行搜索。本文在搜索框处的设计比较智能,用户无需手动选择是搜索作者还是图书,应用会自动甄别内容,并且将最合适的内容呈现给用户。
用户在热搜图书部分如果点击一本图书之后,会进入图书详情界面,这个界面中有图书的名字、作者、ISBN、出版社、图书简介等等详细信息,并且用户可以点击作者名字进入作者详情界面,查询作者的其他图书,除此之外,用户还可以进入出版社的详情界面,查询出版社出版过的图书列表。
当用户点击搜索按钮之后,会得到一个关于搜索内容的列表,这个列表是按照相关度排序的,用户也可以手动选择排序依据,如出版时间、用户评价等等。在这个列表中,用户仍然可以点击某个图书进入详情,在图书详情页面显示的内容和可以进行的操作和从热搜图书进入的图书详情页是一样的。
1.3 架构设计
项目整体的架构以后端为主,前端的设计比较简单,所以这里只列出并且介绍后端的部分,整体架构如图2所示。
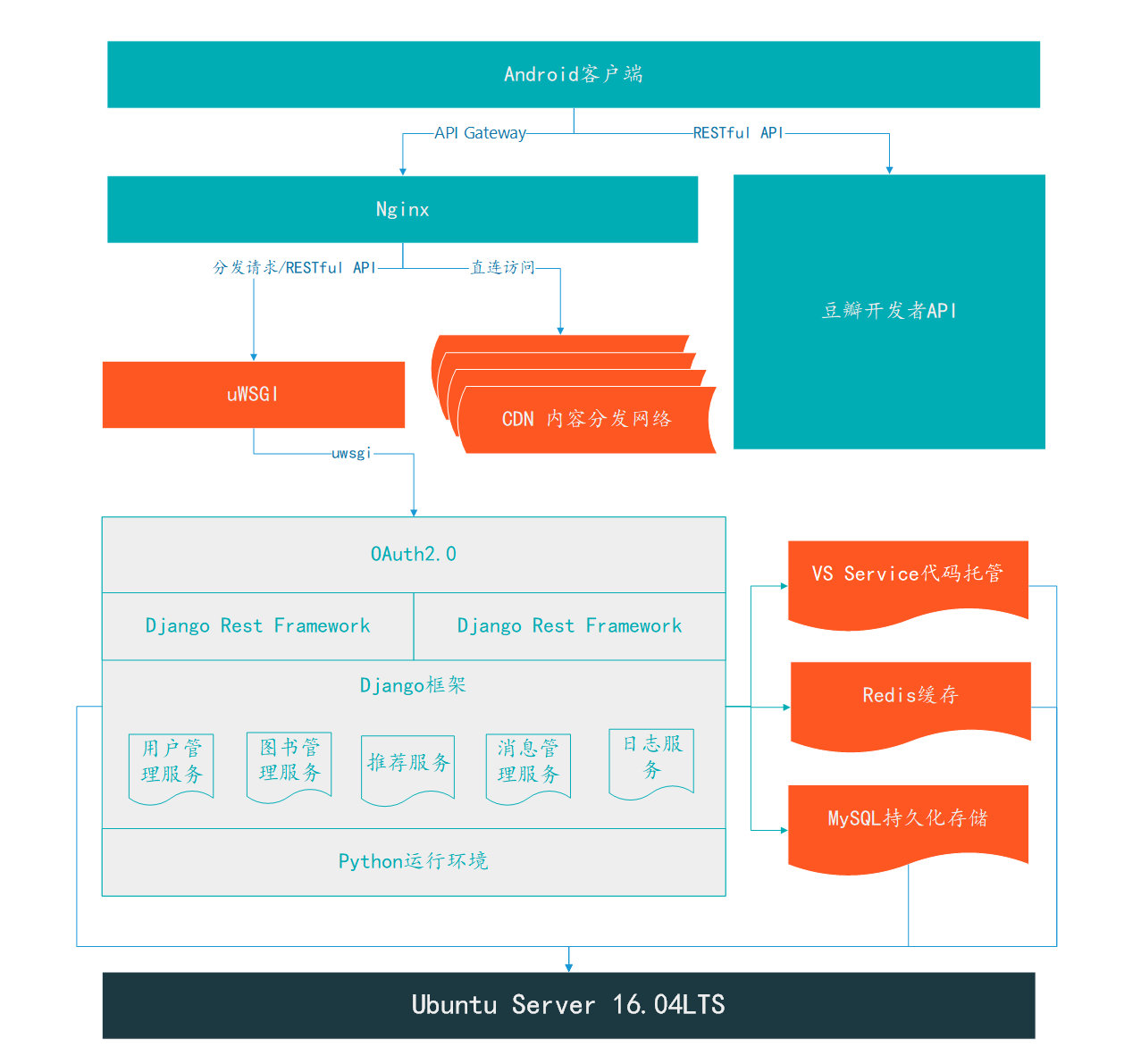
图2 图书管理系统后台架构
1.3.1 Android客户端
这一层表示用户直接操作的部分,是服务器和用户沟通的窗口。
1.3.2 反向代理层
这一层使用Nginx服务器来进行反向代理,Nginx接收客户端发来的请求,并进行请求的分发,将静态资源的请求分发给CDN,将其他请求分发给uWSGI服务器实例。
1.3.3 服务器实例层
uWSGI是真正进行数据处理和响应的服务器实例,由若干实例组成,分别完成不同模块的请求任务,以此来动态调配资源和提高响应速度,增强容灾能力。
1.3.4 核心服务层
底层的是Python运行支持环境,为所有的后端模块提供环境支持。在Python运行支持环境之上是Django框架层,在这一层中,我们使用Django框架实现了用户管理模块、企业管理模块、身份验证模块、扩展模块以及日志模块。这几个模块分别运行在不同的uWSGI服务器实例中,以实现功能和维护的解耦。这些不同的后端模块进行通信的使用的是RPC(远程过程调用)/MessageQueue(消息队列)/RESTful API的方法。
1.3.5 外部服务层
这一层是不必依赖于Django框架的外部服务,分别有豆瓣提供的开发者接口服务,用于进行图书的查询;Github代码托管服务,用于托管和维护代码;Redis缓存服务,用来对频繁读写的数据进行缓存,如位置管理模块中的大量位置都是放置在Redis缓存中,以快速响应频繁的读写,并分担数据库的压力;MySQL持久化存储服务,这一层用于持久化存储各个模块中产生的模块;RabbitMQ消息队列服务,用于提供进程间通信的功能。
1.3.6 服务支持层
这一层包含了服务运行的容器以及底层硬件。上述的所有服务都是运行在64位的Ubuntu Server 16.04操作系统之上的。
2 应用实现
2.1 开发环境
系统的开发环境为Windows 10 64位专业版操作系统。
2.2 开发工具
Android Studio,PyCharm,Butterknife框架,okhttp框架,Django框架,Django-rest-framework框架,MySQL数据库,Redis缓存数据库,uWSGI服务器,Nginx服务器。
2.3 开发过程
整体开发过程使用敏捷开发方式,首先确定豆瓣API的接口规格,然后定制数据库Schema,并实现服务端的架构和功能。关于客户端,一共分为几个界面:首页、图书详情、图书列表、作者详情和出版社详情,这几个界面基本都是独立的,设计完样式和逻辑之后,直接使用okhttp和服务器以及豆瓣API进行交互即可。
3 结论
在互联网飞速发展、大众对阅读(特别是高质量的图书)的需求越来越高的形势下,电子阅读正在受到更多人的青睐,但同时也存在着许多不足之处。本文所介绍的这款Android平台的图书查询APP,是自主设计的,拥有丰富的图书涵盖量和简便的操作功能,因此可以较好地满足大众的阅读需求,让人们享受到便利的图书查询服务;与此同时,此APP还能很好地保护用户的个人信息,确保图书查询过程中的安全性。尽管此APP还有功能较少等美中不足的地方,但它的发展前景仍相当可观。
针对APP自身的不足之处,未来要在保证人们查询图书的效率不受影响的前提下对APP的功能进行拓宽和完善,在这过程中不断发现不足并加以弥补;另外,将通过朋友亲人推荐、登陆应用商店等多种方式进行推广运营,让更多的人能够享受到这款APP带来的图书查询的便利。
参考文献
[1]张广泉,刘艳.基于UML的图书管理系统体系结构模型及实现[J].重庆师范大学学报(自然科学版),2005,22(2).
[2]顾俐.图书馆图书管理系统的设计[J].中国科技信息,2007,(2).
[3]公磊,周聪.基于Android的移动终端应用程序开发与研究[J].计算机与现代化,2008,(8).
[4]刘班.基于Django快速开发Web应用[J].电脑知识与技术,2009,5(7).
[5]李凌.基于开放API的图书笔记手机应用的设计与实现[J].图书馆学研究,2015,(4).
[6]黄健荣,郭昌言,于萧榕.基于Android系统的图书管理的研究与应用[J].信息技术,2012,(7).
[7]孙华林,夏利青.Android平台移动图书管理App的构建与实现[J].电脑知识与技术,2015,11(15).
(梁山县第一中学)





