1 引言
生物信息学是一门新兴学科。随着人类基因计划的开展,尤其是测序技术的发展,基因组学每天都要产生数以“T”计的海量数据。GenBank数据库是美国国家生物技术信息中心的DNA序列总数据库。截至2017年,仅记录在GenBank中的DNA序列总量就已超过了70亿个碱基对。毫无疑问,生物大数据的积累会愈发增多。GEO(GeneExpression Omnibus)是美国国家生物技术信息中心(NationalCenter for Biotechnology Information,NCBI)下的基因表达数据库,GEO中已存储了3848个数据集,包括1618438个样本的基因表达、基因芯片、蛋白质结构信息等数据。而在这些数据的基础上派生、整理出来的数据库已超过500个。图1统计了GEO中从2000年到2015年存储样本数据的变化情况。
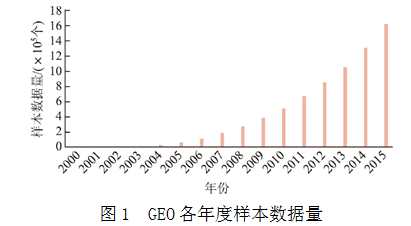
显然,这些数据必须经过整理、分析才能给人们带来收益。对于海量数据,分析手段主要是整合、评价和挖掘。本文将基于模糊综合评判和数据包络分析,提出一种针对生物信息大数据的数据分析方法。
2 理论模型和方法
2.1 模糊评判
模糊综合评判是决策论中最常用的一种方法。在实际中,常常需要对一个事物做出评价,而评价往往涉及多个因素或多个指标,此时就要求根据这些因素对事物做出综合评价。这些因素并不都是确定性的,具有随意性和模糊性。模糊综合评判是以模糊数学为理论基础发展而来的一种方法。


2.2 数据包络分析
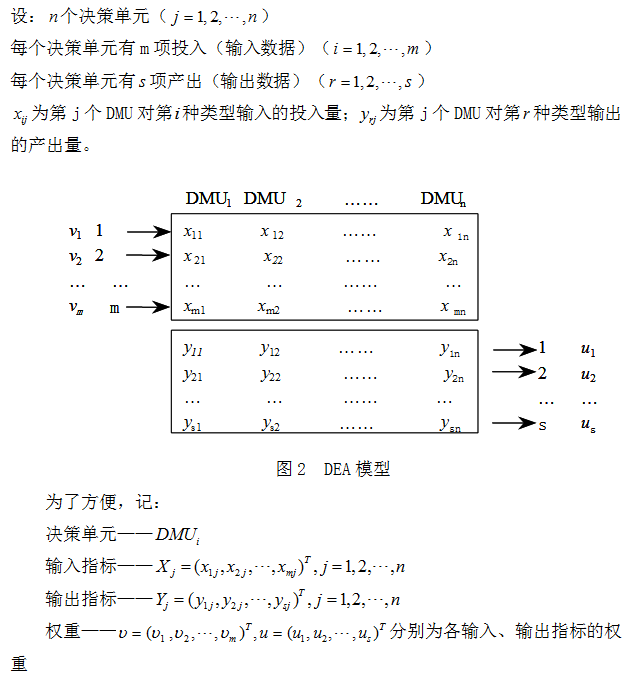
在DEA中一般称被衡量绩效的组织为决策单元(decisionmaking unit,DMU)。假设各决策单元的输入数据和输出数据由图2给出。




这就是某蛋白质在四个因素的评价结果。该蛋白质在两个受体上的活性和水溶性表现较好,但是纯度和形状这两个因素导致贡献度较差。因此,可以从提高纯度和改变形状这两方面着手,研发下一代蛋白质合成技术。
4 结论
本文基于DEA理论的模糊综合评判方法,提出了基于DEA模型的生物信息大数据模糊综合评判方法。以某蛋白质对提高人体免疫力贡献度的评价为例进行了算例验证,算例表明该方法克服了模糊综合评判方法的缺点,更具客观性,计算效率高。
参考文献
[1]任艳姣.生物信息学数据整合的应用研究[D].长春:吉林大学,2012.
[2]Benson D A, Karsch-Mizrachi I,LipmanD J,et al.GenBank[J].Nucleic Acids Research,2000,28(1).
[3]杨纶标,高英仪,凌卫新.模糊数学原理及应用[M].5版.广州:华南理工大学出版社,2011.
[4]谢季坚,刘承平.模糊数学方法及其应用[M].2版.武汉:中华科技大学出版社,2000.
[5]黄朝峰.高效办学效益模糊DEA评价[M].北京:中国经济出版,2009.
[6]魏权龄.数据包络分析[M].北京:科学出版社,2004.
[7]马占新,等.基于模糊综合评判方法的DEA模型[J].糊系统与数学,2001,15(3).
[8]N. Adler,L.Friedmanand Z. Sinuany-Stern,Review of ranking method indata envelopment analysiscontext[J].EuropeanJournalofOperational Research,2002,(140).
[9]P.Andersen and N.C. Petersen, A procedure for rankingefficient units in data envelopment analysis[J].ManagementScience,1993,39(10).
[10]杜东.第八届中国青年运筹信息管理学者大会论文集[C].桂林:基于DEA模型的模糊综合评判方法,2006.
[11]李冠.顾客满意度的模糊DEA评价[J].山东科技大学学报(自然科学版),2001,20(4).
[12]杜东.模糊DEA方法及其在人才评价中的应用[J].运筹管理与21世纪的中国[A].北京:宇航出版社,1997.
[13]姜启源,谢金星,叶俊.数学模型[M].3版.北京:高等教育出版社,2003.
(盖州市第一高级中学)





